Topics
March 11, 2025



March 11, 2025
Kevin Johnson is Head of AI at Dscout. This article is adapted from a presentation he gave at Co-Lab Continued, “Decoding AI Fundamentals”.
Last year at Co-Lab, I gave a talk on a GenAI primer, where we talked about some of the very basic fundamentals of this new technology—and how even the people who created it don't know how it works. We have emergent capabilities, and no one even understands what is possible.
We got a lot of positive feedback demystifying this technology. Now we're going to dig deeper and pick up exactly where we left off.
The main takeaway from last year was that AI intelligence is not the same as human intelligence—it's using massive amounts of data to predict the next word.
Let’s dig into the data component.
LLMs are trained on massive amounts of data. Each one has their own unique data and their own unique set of parameters to train it.
For a prompt like, “AI ‘intelligence’ is not the same as human intelligence. AI is using massive amounts of data to predict the next…”
They’re all unique and the data that’s underlying these products drives this. And with these responses, AI is simulating the appearance of cognitive abilities.
We commonly forget that it's not cognitive in the responses. LLMs are definitely not thinking the same way we are.
When we interact with LLMs, we provide some text input, and we expect some text output. The way that you interact with these elements is through prompting.
For example, to get these LLMs to predict the end of that sentence, I needed to prompt with this…
“I am going to provide you with a phrase. I would like you to complete the next word to this phrase.
Phrase: AI ‘intelligence’ is not the same as human intelligence. AI is using massive amounts of data to predict the next…”
You can see that you have to provide some instructions along with the prompt as well to get it to predict the next word.
“Training” is a term that I've seen confusion around. When AIs are trained, they take massive amounts of data—often petabytes of data—and they structure it into prompt and response structures.
Big companies use thousands of GPUs to train these LLMs. They run computational programs for weeks and months to get these models. This is computationally expensive and monetarily expensive, and there are only a few big companies out there that produce these really big models.

However, there are a lot of smaller versions of them. When they train smaller LLMs, they have to structure it into prompt and response structures.
Below is a real example to show how we can use our own underlying data to improve LLMs.
This example was released to general availability production back in July. It’s a question-level theme filter. When you run an unmoderated study in Dscout, you might have 20-30 questions in your study. Some are open-ended and some are screenshare, but there can be many other types as well.

Let's say you had 100 different respondents take this mission, and they each made five-minute-long videos. Trying to analyze so much data can be overwhelming. We decided to help researchers tackle this problem and landed on a particular feature.
At the question level, we provide a qualitative theme list of commonly occurring themes within that question. You quickly click on each one of these and see the responses that are related to it. The idea is to give you a jumping-off point to help with that overwhelming feeling when first analyzing many qualitative responses.
One of the main takeaways here is that after months and months of work, we’re now seeing about 25 percent time savings in doing the analysis. It's a huge benefit.
We work with these LLMs through prompting (this can be through an API as well). Here's the prompt I first came up with…

I told the LLM I was going to provide a question and unique responses. I wanted a bulleted list back.
Remember, we're building a product here, so the output needs to be structured in a way that we can automate and produce this type of interaction for the user.

Unsurprisingly, the output was not what we needed to produce this. It added headers where I didn’t want them, sub-bullets, and it even added a paragraph that I removed from the slide. Sometimes the LLM even switched perspectives and even hallucinated…so that obviously wasn’t going to work.
We had two major ways to influence these outputs to be higher quality for our needs: one is through putting more data into this prompt. The data that's in this prompt is called context.
There's some confusion around context versus prompting.
Prompt is how you interact.
Context is the data that's in the prompt.
Context is the information that you're putting into a prompt, or the information that the LLM is using in that next word prediction. It's the actual text itself. That's one method.
With this method, you can inject real-life examples and put in real data. When you feed this to the LLM, that data is not being put into the model itself—it's only being used by the model at time of prediction. That's a huge differentiator.
When you ask questions about how people are using your data, or how you're going to use your customer's data, with this technique you're not injecting that information into the model itself. There are certain pipelines you can set up with LLM providers called zero retention or no retention.
Zero retention is an important consideration when signing up. If you don't sign up for one of those, the providers can use your data later to then retrain a model, so be sure to look at the details.
But aside from that, when you're using data in this way, and if you have that type of pipeline, your data is not going into the model itself.
From our experience we’ve found as you're starting to work with LLMs to build products, a zero-retention approach is a good way to start.
The other option that you have is changing the model itself.
With the second approach, you can go with a completely different LLM to change the output as well. For example, if you use ChatGPT 3.5, you could also consider using 4.0 or going with a different provider like Google Gemini or Copilot.
You can even take this one step further and take your own data to influence an LLM.
Take your data or your customer's data, then structure it into prompt and response structures and inject it into this model. The model has already been trained, so injecting this data in there is termed “fine-tuning”. We should differentiate between “training”—which is the initial creation of the model—and “fine-tuning”, which is taking your problem-specific data and training a few steps further.
When you fine-tune you have to be very careful. What you're telling the LLM is: “Specifically remember this data, and start to forget the other data that you had before in previous training.”
By consequence, some of the emergent capabilities previously in the model start to disappear. The LLM starts to memorize the responses. This is where it can start injecting exact responses, rather than making up the best mathematical probability response.
When you're taking these two different approaches, remember that when you put it in the context, the models used at the time of prediction are not going into the model.
When you're fine-tuning, the data is going into the model. The model remembers when giving this prompt, this is the response.
Now we can ask better questions about:
Doing these evaluations, setting up the guide rails, and working with the tech teams are the hard parts of this approach. We've worked really hard at Dscout the past year on these processes.
AI intelligence is not the same as human intelligence. It's using massive amounts of data to predict the next word. How it's using that data can be done in many different ways. From training, you can put it in your own context and fine-tune. The best, highest-quality word for your particular application is based on the human evaluation you do to get there.
“We should differentiate between ‘training’—which is the initial creation of the model—and ‘fine-tuning’, which is taking your problem-specific data and training a few steps further.”
Let’s return to our problem and initial prompt. What are our options?

We can see some issues with the response and start adding more instructions in here.
Consider putting guardrails around things like…
Remember as you add new lines, the model does start to forget other previous lines. Every small change, you have to reiterate and check everything you've done previously because it can start forgetting things or not pay attention to your instructions.

Consider a chain of thought approach: break a complex problem into substeps. The AI will go through this in steps and check its work along the way. Instead of producing an output all of a sudden, it will produce multiple outputs, until it gets to the very end and then write out what the final step is.
Between these two options, how do you know which one's better?

This is where human evaluation becomes very important. Above, we have the outputs from both option A and option B.
At Dscout, throughout a difficult 9-10 month process, we worked with our UXR team. We did iterations with the tech team—human UXRs evaluated various options and provided feedback to our tech team. We set up systems and documentation around this.
We kept iterating until we got to the final output. This was months and months of iterations, just for one question and set of responses shown here.
When you look at a study, you have…
There are some studies with ten participants, some with hundreds of participants. We needed to set up a big design of experiments and have our UXRs evaluate all these different question types as we make small changes to various prompts along the way—and use this ranking technique to keep track of everything to get to a final solution. In the final solution, we ended up with what we have today after 9-10 months of hard work.
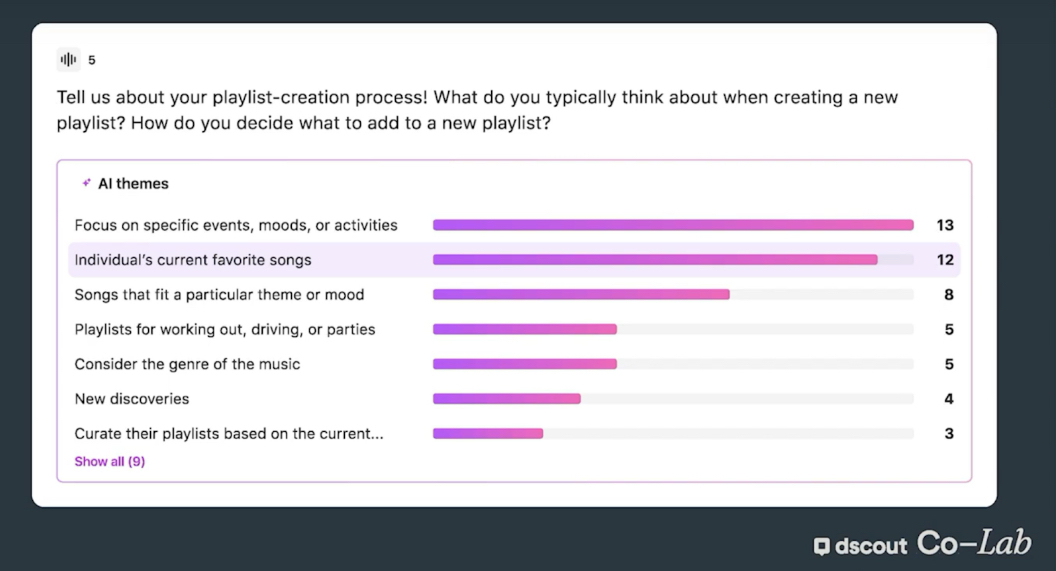
I narrowed in on “one solution” but in reality, it ended up being six or seven different complex pipelines to get to this type of output where we’ll do checks along the way and try alternate approaches if we feel like the list is low-quality and we have signals.
So in our evaluation projects with the UXRs, we started to note things that we knew were not high-quality or if there was more overlap in themes or if there were some subjective terms in the themes.
We’ll actually evaluate different pipelines and present the best results.
I bring this up because companies are taking very different approaches to this. It’s now easier than ever just to put an LLM behind a product, roll it out to the world, and say, “We can do all these things!”
When you're considering any product or building a product for yourself, it’s important to look at the human evaluation piece and evaluate how they're evaluating and using data. You need the right guardrails in place.
Because it’s very easy to just build a product and say, “It’s amazing!” when it’s all the same LLM in the background and they don’t have the right guide rails in place. And doing these evaluations, setting up the guide rails, and working with the tech teams is the hard part.
That’s something we’ve worked really hard on over the past year at Dscout.
When you're considering any product or building a product for yourself, it’s important to look at the human evaluation piece and evaluate how they're evaluating and using data. You need the right guardrails in place.
AI intelligence is not the same as human intelligence—it uses massive amounts of data to predict the next word. How it’s using that data can be done in many different ways.
From training, you can put it in your own context, do fine-tuning, and the best, highest-quality word for your particular application will be based on the human evaluation you do to get there.