Topics
June 5, 2026


June 5, 2026
Enterprise design and research teams are under a familiar kind of pressure: Do more! Do it faster! But make sure every decision is grounded in real human insight!
AI naturally has become one of the most discussed answers to that challenge, but how teams are actually using it looks a lot more nuanced than the hype suggests.
Here are a few key things that enterprise teams are figuring out in practice.
The most consistent pattern across teams using AI well? They're applying it to the parts of the research process that have always been slow without handing over the parts that require human judgment.
At Affirm, researchers ran a 1,500-participant study pairing quantitative benchmarking with qualitative depth. Mamie and her team used Dscout's AI features to speed up the analysis process and synthesize findings, but the human team members remained responsible for interpreting meaning and aligning stakeholders across the org. The team used this work to ultlimatley influence product, design, business intelligence, and sales. At the end, one study became a living research asset the whole org continues to use.
This is an AI-scale model that actually works! Humans set the direction and made the decisions, while AI handled the labor of sorting, summarizing, and surfacing. A project of that scale was no small feat, but they were able to achieve it with AI assistance.
One of the more significant shifts happening at the enterprise level is expanding research across teams (sometimes called democratization). This is the idea that not just trained researchers, but PMs, designers, and engineers, can contribute to quality research.
AI tools can help lift a lot of the time-intensive research work. Things like: flagging poor-quality screener videos, following up with participants, taking a first draft at study design and follow-up question, initial tagging, auto-transcriptions, etc.
These tools can help lighten the load (especially for designers or newer researchers) while allowing for human judgment and decision-making.
For example, with Dscout AI Studio, designers can describe what they're trying to learn, and the AI generates a ready-to-run study design. They then have the option to launch AI-moderated studies, collect responses in hours, and use a conversational interface to analyze results and create shareable artifacts.
This is a massive tool if you’re trying to run a quick usability test or get video responses from a large sample of users. This type of research is easy to scale while maintaining quality.
To dig into this further, we’ve also put together a free email course on using AI to scale research.
There's a quieter conversation happening inside a lot of enterprise product teams: who should own AI evaluations?
Nathan Reiff (Product Manager at Dscout) makes the case that researchers are the natural fit. Not because they're the most technical, but because they're the most connected to what users actually need.
In AI development, someone has to serve as the subject matter expert who reviews early outputs, identifies where the model is going wrong, and keeps the work grounded in real user goals.
Researchers do that naturally because they are consistently close to the end-user. They bring the qualitative lens that prevents AI products from optimizing for the wrong thing, and they can bridge evaluations with real user research to make product decisions that actually hold up.
If AI evaluations are something your team is exploring, we also put together The People Nerds Guide to AI Evaluations. It breaks down what AI evals are, how they work, and why research teams are especially equipped to run them properly.
For teams that want to bring AI into their research workflow but aren't sure where to start, frameworks are emerging that make the process more systematic.
Laurel Brown (Senior UX Researcher at Dscout) and Nikki Anderson (Founder of The User Research Strategist) have developed a set of approaches that treat AI as a thought partner rather than an oracle.
A few highlights worth knowing:
The clarity chain turns vague stakeholder requests into structured research questions by iterating through prompts—dropping in the ask, reframing it, expanding scope options, and generating a clean kickoff summary.
The research pre-mortem asks AI to simulate how a study could fail before it launches. Prompts like "what's the worst part of this study design?" surface weaknesses early, when they're cheap to fix.
The participant mirror uses AI to identify who's being unintentionally filtered out of a study—the gaps in recruitment that researchers can miss when they're too close to the problem.
They also put together a guide on How to Build Better Products with AI-Supported Research for more strategies on prompting AI and how to use this tech to build more confidently.
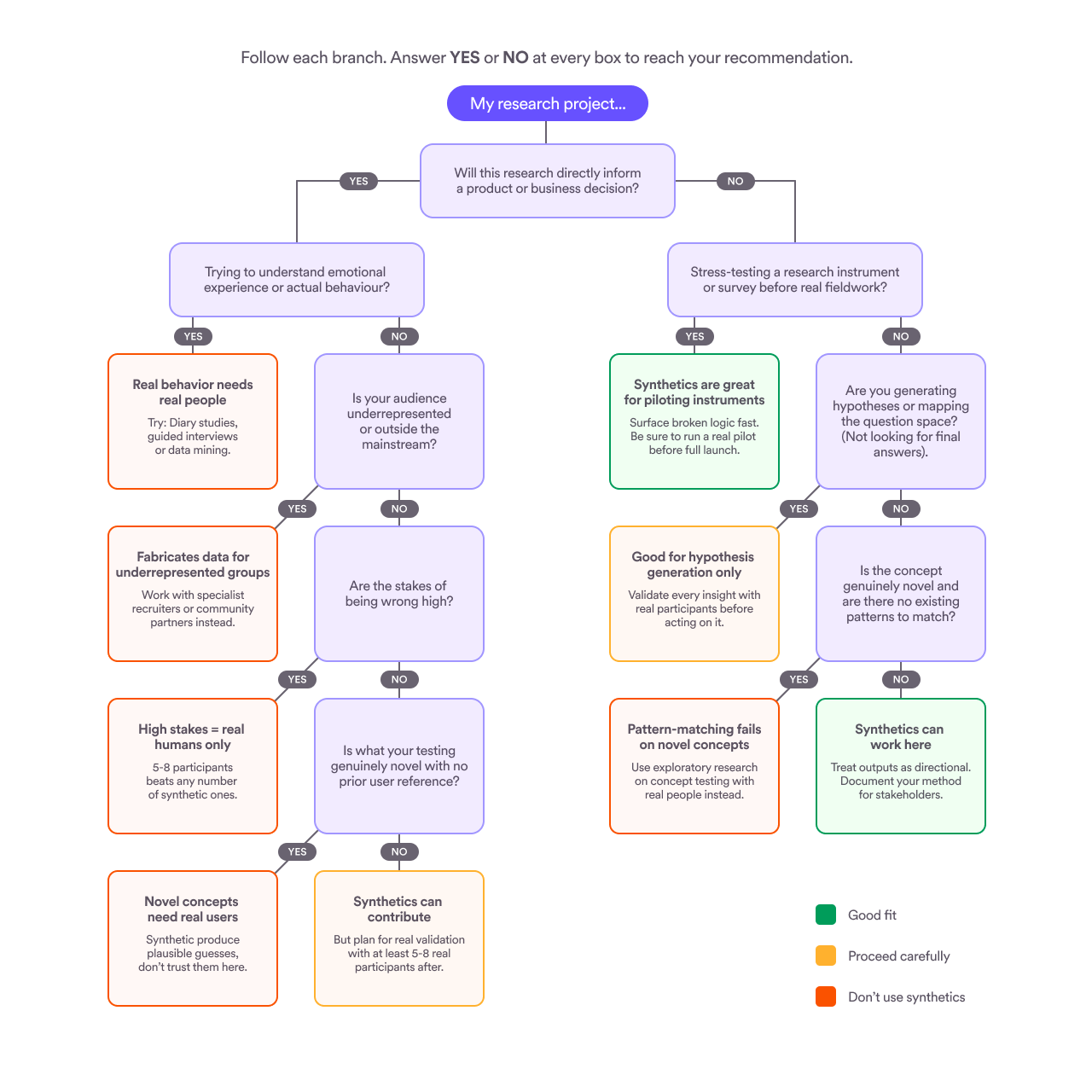
One of the sharper debates in enterprise research right now is when (and whether) to use AI-generated synthetic participants.
The truth of the matter is, synthetics can be useful for things like stress-testing your research design, exploring edge cases, and pressure-testing assumptions. They're a fast, low-cost way to refine and ask better questions before you spend real research budget.
But for anything that will directly inform product decisions, behavioral research, or studies involving underrepresented groups, real human participants are essential.
Synthetic research can look like research—it has sample sizes, themes, and quotes—but it reflects patterns from the past, not the messy reality of people in the present. The risk of false confidence is real.
The practical rule of thumb: use synthetics to figure out what questions to ask, then get real humans to answer them.
We also put together a quick chart to help you decide if synthetic participants are a good choice for your project.
As enterprise teams ship AI features at scale, safety has moved from a legal and engineering concern to a core design responsibility.
Gray Swan AI’s Meredith McDermott (UX Lead, formerly of Duolingo) and Marysia Winkels (AI Safety Engineer) argue that UX practitioners are uniquely positioned to lead safety work because safety failures are fundamentally experience failures. A hallucination that gives a customer the wrong price doesn't just annoy them; it destroys trust in the product.
The toolkit they put together includes building rubrics for what "good" looks like before training or launching a feature, using red teaming to intentionally try to break your own product, and treating safety as a design constraint that's present from the start (not a final gut-check you have to check off).
The teams at Headspace applied a version of this when building Ebb, their AI-powered reflection experience. Folks were initially skeptical about where and when to build customer-facing AI tools given the sensitive mental health context, but the team was extremely thoughtful and and tested placement/use case rigorously.
They ran things like desirability studies, diary studies, voice-flow prototyping, and multiple rounds of internal red teaming, and invited employees across the org to test vulnerabilities.
At the end, Ebb became an AI experience that earned customer and team trust, it wasn’t just forced adoption.
Traditional UX measurement is built for deterministic products: define the task, observe completion, measure errors… but GenAI breaks that model.
Kevin Newton (Senior Manager of User Experience Measurement at LinkedIn) talks about this during his Co-Lab session. GenAI products have near-unlimited use cases that researchers can't fully anticipate, so how do we measure the success of something we can’t necessarily predict?
A few interesting examples come from Susan Kresnicka and Karis Eklund over at KR&I where they walked through ways that customers and fandoms are using AI. Some things were expected, like using AI as a teacher to distill and summarize dense information.
But others were more surprising, like using AI as a companion to discuss specific interests. For example, one participant used AI to chat in-depth about a favorite One Piece character.
Difficult to predict! But in Newton’s talk, he recommends treating the AI itself as the "user" being measured. Instead of measuring task completion rates, measure output success rates. Instead of measuring time-on-task, measure how long the model took to deliver. Instead of measuring things like user errors, measure model errors.
Afterward, bring humans in as harsh critics. Ask things like, “Did the AI actually deliver on what the person intended?” If it isn't changing users' lives in some meaningful way, the feature probably isn't being used correctly.
Across all of these use cases: faster analysis, democratized research, AI-led evals, safety testing, GenAI measurement—the throughline is the same: AI is most valuable when it's in service of human understanding.
The teams doing this well aren't replacing researchers with AI. They're using AI to help researchers, designers, product teams, etc. ask better questions, surface what they might miss, move faster on low-stakes tasks, and spend more of their time on the work that requires real judgment.
Dscout AI Studio was built to help teams move faster without leaving human insight behind. See how it works.